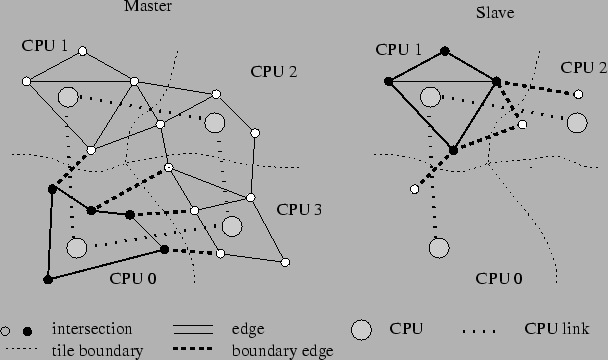
Domain decomposition might be defined as partitioning the geographical region into subregions of approximately equal size (Fig. 1). It is one of the crucial issues of parallel computing. After partitioning the domain into subdomains, each CPU in the system is assigned to one of these subdomains and performs the calculation on that subdomain.
|
|
Since some of the vehicles in the traffic might leave a subdomain and enter into another subdomain on the way to their destinations, the traffic flow information near the boundary of the neighbor subdomains (or CPUs) needs to be exchanged. This is necessary in order to maintain the consistency between the CPUs.
In the following, we will describe the domain decomposition method for the cellular automata (CA) implementation which is used in TRANSIMS [12]. That particular implementation, however, is used for exposition only; the parallelization approach works on any driving logic which has a similar structure. The domain decomposition for parallelization is straightforward if the state at time t+1depens only on information from time step t, and on neighboring cells. Therefore, an updating process in such a system is in principle composed of two elements, namely, a communication for the boundary information at time step t, and an update from time step t to t+1. In the actual implementation, we use two communcations and two sub-updates per time step, see later.
Traffic simulations fulfill two conditions which make this approach efficient:
We decided to cut the street network in the middle of links rather than at intersections; THOREAU [7] does the same. This separates the traffic complexity at the intersections from the complexity caused by the parallelization and makes optimization of computational speed easier.
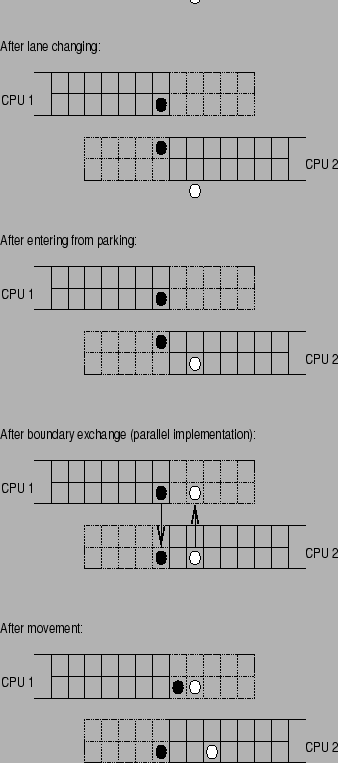
In the implementation, each divided link is fully represented in both CPUs. Each CPU is responsible for one half of the link. In order to maintain consistency between CPUs, the CPUs send information about the first five cells of ``their'' half of the link to the other CPU. Five cells is the interaction range of all CA driving rules on a link. By doing this, the other CPU knows enough about what is happening on the other half of the link in order to compute consistent traffic. Therefore the resulting simplified update sequence on the split links is as follows (Fig. 2):
|
|
Note, however, that use of the CA can be viewed as a didactic example; any traffic simulation logic where the state at time t+1 uses only information from time t and where interaction is local can be parallelized in this way.