Graph partitioning is a technique for executing a set of tasks in parallel so as to balance the load and minimize communications among processors. Once we are able to handle split links, we need to partition the whole transportation network graph in an efficient way. Efficient means several competing things: Minimize the number of split links; minimize the number of other domains each CPU shares links with; equilibrate the computational load as much as possible.
There are several algorithms and software for graph partitioning. One approach to domain decomposition is orthogonal recursive bisection. Although less efficient than METIS (explained below), orthogonal bisection is useful for explaining the general approach. In our case, since we cut in the middle of links, the first step is to accumulate computational loads at the nodes: each node gets a weight corresponding to the computational load of all of its attached half-links.
Nodes are located at their geographical coordinates. Then, a vertical straight line is searched so that, as much as possible, half of the computational load is on its right and the other half on its left. Then the larger of the two pieces is picked and cut again, this time by a horizontal line. This is recursively done until as many domains are obtained as there are CPUs available.The orthogonal bisection for Portland 200000 links network is shown in Fig. 4. It is immediately clear that under normal circumstances this will be most efficient for a number of CPUs that is a power of two. With orthogonal bisection, we obtain compact and localized domains, and the number of neighbor domains is limited.
Another option is to use the METIS library for graph partitioning [4]. METIS uses multilevel partitioning. What that means is that first the graph is coarsened, then the coarsened graph is partitioned, and then it is uncoarsened again, while using an exchange heuristic at every uncoarsening step. The coarsening can for example be done via random matching, which means that first edges are randomly selected so that no two selected links share the same vertex, and then the two nodes at the end of each edge are collapsed into one. Once the graph is sufficiently collapsed, it is easy to find a good or optimal partitioning for the collapsed graph. During uncoarsening, it is systematically tried if exchanges of nodes at the boundaries lead to improvements. ``Standard'' METIS uses multilevel recursive bisection: The initial graph is partitioned into two pieces, each of the two pieces is partitioned into two pieces each again, etc., until there are enough pieces. Each such split uses its own coarsening/uncoarsening sequence. k-METIS means that all k partitions are found during a single coarsening/uncoarsening sequence, which is considerably faster. It also produces more consistent and better results for large k.
The number of split links from METIS can be approximated as
![]() for the
20024-links network mentioned above; for a higher
resolution network with 200000 links we obtain
for the
20024-links network mentioned above; for a higher
resolution network with 200000 links we obtain
![]() [6]. p is the number of
CPUs. The orthogonal bisection method, on the other hand, scales
Nspl as
[6]. p is the number of
CPUs. The orthogonal bisection method, on the other hand, scales
Nspl as
![]() .
Therefore, METIS considerably reduces the
number of split links.
.
Therefore, METIS considerably reduces the
number of split links.
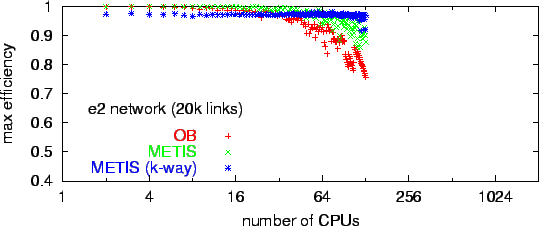
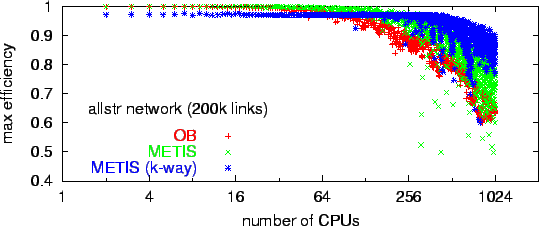
Such empirical results on graph partitioning can be used to compute the theoretical efficiency. Efficiency is optimal if each CPU gets exactly the same computational load. However, because of the granularity of the entities (nodes plus attached half-links) that we distribute, load imbalances are unavoidable, and they become larger with more CPUs. We define the resulting theoretical efficiency due to the graph partitioning as
where the load on the optimal partition is just the total load divided by the
number of CPUs. We then calculated this number for actual partitions of both
of our 200000 links and of our 200000links
Portland networks as shown in Fig. ![]() (from [11]). The result shows
that, according to this measure alone, our 200000 links network
would still run efficiently on 128 CPUs, and our 200000links
network would run efficiently on up to 1024 CPUs.
(from [11]). The result shows
that, according to this measure alone, our 200000 links network
would still run efficiently on 128 CPUs, and our 200000links
network would run efficiently on up to 1024 CPUs.