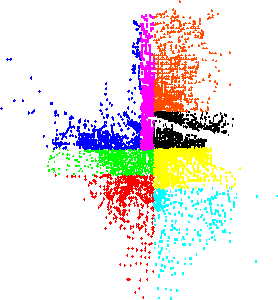
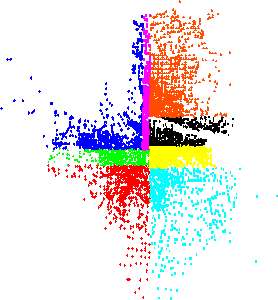
Load balancing is an important issue for a parallel system. It should be solved in order to enable the efficient use of parallel computer systems such that the loads on different CPU should be as similar as possible and all CPUs should be kept busy as much as possible.
The efficiency measure from the last section gives information about probable load imbalance due to the granularity of the smallest units, which are the nodes with attached half-links. The approach in that section assumes that the computational load of those units depends on the lengths of the attached links only. Some applications, such as traffic simulations, do not have constant computational loads on those units, because the computational load depends on the number of vehicles on those links which in turn depends on traffic. Thus, we should optimize the average response time of both single tasks and the overall application in parallel in order to provide equal load on the CPUs and to minimize delays in data communication between these CPUs.
There are several common approaches to adaptation of the load balancing. One idea is alternating between a few different methods by defining a system as heavily, medium or lightly loaded and issuing different policies for each situation.
Another approach, that is used here, is to learn from the outputs of the previous runs. The loads on CPUs depend on the actual vehicle traffic in the respective domains. Since we are doing iterations, we are running similar traffic scenarios over and over again. We use this feature for an adaptive load balancing: During run time we collect the execution time of each link and each intersection (node). The statistics are output to file. For the next run of the micro-simulation, the file is fed back to the partitioning algorithm. In that iteration, instead of using the link lengths as load estimate, the actual execution times are used as distribution criterion.
Fig.4 (right) shows the new domains after adaptive load balancing has been employed. One clearly sees that the sizes of the domains are different from the partitioning of the empty network (Fig. 4 left).
|
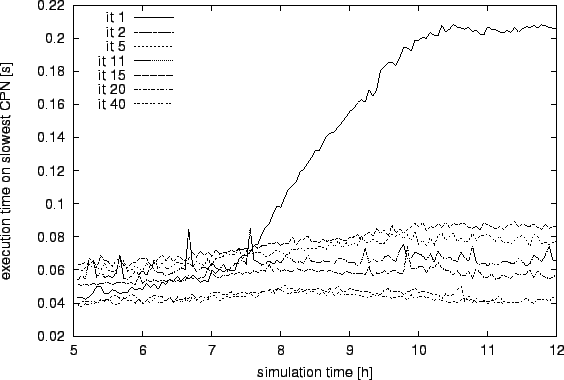
To verify the impact of this approach, we monitored the execution times per time-step throughout the simulation period. Figure 5 depicts the results of one of the iteration series. For iteration 1, the load balancer uses the link lengths as criterion. The execution times are low until congestion appears around 7:30 am. Then, the execution times increase fivefold from 0.04 sec to 0.2 sec. In iteration 2 the execution times are almost independent of the simulation time. Note that due to the equilibration, the execution times for early simulation hours increase from 0.04 sec to 0.06 sec, but this effect is more than compensated later on.
The figure also contains plots for later iterations (11, 15, 20, and 40). The improvement of execution times is mainly due to the route adaptation process: congestion is reduced and the average vehicle density is lower. On the machine sizes where we have tried it (up to 16 CPUs), adaptive load balancing led to performance improvements up to a factor of 1.8. It should become more important for larger numbers of CPUs since load imbalances have a stronger effect there.
|
|