Now more than two choices, e.g.:
Go swimming, go shopping, stay home, go to movies, ...
Many possible times-to-depart (discretized into 5-min bins).
See Fig. 29.4.
![\includegraphics[width=0.8\hsize]{overlap-multi-gpl.eps}](img639.png)
|
Concentrate on option ``1''.
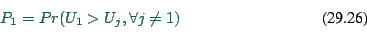 |
(29.23) |
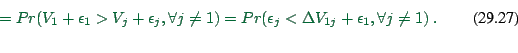 |
(29.24) |
Alternatively:
As in binary choice, a Gaussian distribution will lead to use of the error function. This will not be discussed any further here.
A Gumbel distribution will lead to the use of the logistic distribution.
![]() multinomial choice with Gumbel-distributed randomness.
multinomial choice with Gumbel-distributed randomness.
We had:
![\begin{displaymath}
P_1 = Pr\left[
\epsilon_1 > \max_{j \ne 1}[ \Delta V_{1j} + \epsilon_j ]
\right] \ .
\end{displaymath}](img642.png) |
(29.26) |
Two steps:
![]() Gumbel-distributed
Gumbel-distributed
![]()
![]() also Gumbel-distributed.
also Gumbel-distributed.
![]() and
and ![]() Gumbel-distributed
Gumbel-distributed
![]()
![]() logistically distributed.
logistically distributed.
Only problem is to keep track of the transformations of the two
parameters ![]() and
and ![]() .
.
Result of second step is (remember: similar to binary logit)
![]()
Either via normalization or via really computing ![]() as the new
as the new
![]() of the Gumbel distribution one obtains
of the Gumbel distribution one obtains
![]()