An important advantage of the CA is that it helps with the design of a parallel and local simulation update, that is, the state at time step depends only on information from time step , and only from neighboring cells. (To be completely correct, one would have to consider our sub-time-steps.) This means that domain decomposition for parallelization is straightforward, since one can communicate the boundaries for time step , then locally on each CPU perform the update from to , and then exchange boundary information again.
Domain decomposition means that the geographical region is decomposed into several domains of similar size (Fig. 1), and each CPU of the parallel computer computes the simulation dynamics for one of these domains. Traffic simulations fulfill two conditions which make this approach efficient:
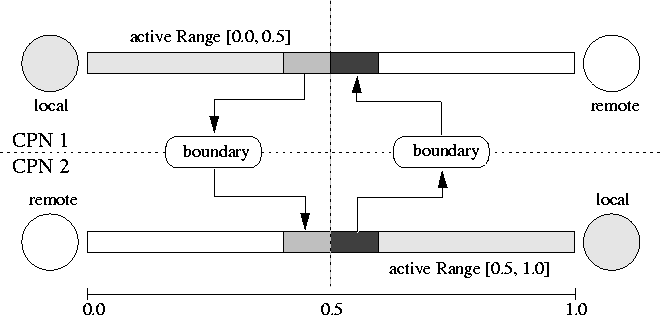
In the implementation, each divided link is fully represented in both CPUs. Each CPU is responsible for one half of the link. In order to maintain consistency between CPUs, the CPUs send information about the first five cells of ``their'' half of the link to the other CPU. Five cells is the interaction range of all CA driving rules on a link. By doing this, the other CPU knows enough about what is happening on the other half of the link in order to compute consistent traffic.
The resulting simplified update sequence on the split links is
as follows (Fig. 3):![]()
The implementation uses the so-called master-slave approach. Master-slave approach means that the simulation is started up by a master, which spawns slaves, distributes the workload to them, and keeps control of the general scheduling. Master-slave approaches often do not scale well with increasing numbers of CPUs since the workload of the master remains the same or even increases with increasing numbers of CPUs. For that reason, in TRANSIMS-1999 the master has nearly no tasks except initialization and synchronization. Even the output to file is done in a decentralized fashion. With the numbers of CPUs that we have tested in practice, we have never observed the master being the bottleneck of the parallelization.
The actual implementation was done by defining descendent C++ classes of the C++ base classes provided in a Parallel Toolbox. The underlying communication library has interfaces for both PVM (Parallel Virtual Machine [30]) and MPI (Message Passing Interface [24]). The toolbox implementation is not specific to transportation simulations and thus beyond the scope of this paper. More information can be found in [34].
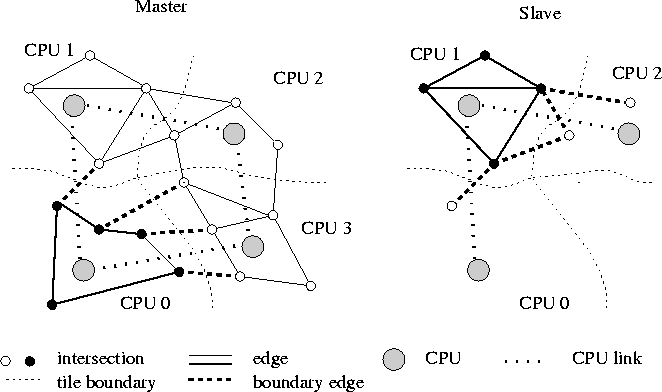
Figure 1: Domain decomposition of transportation network. Left: Global view. Right: View of a slave CPU. The slave CPU is only aware of the part of the network which is attached to its local nodes. This includes links which are shared with neighbor domains.
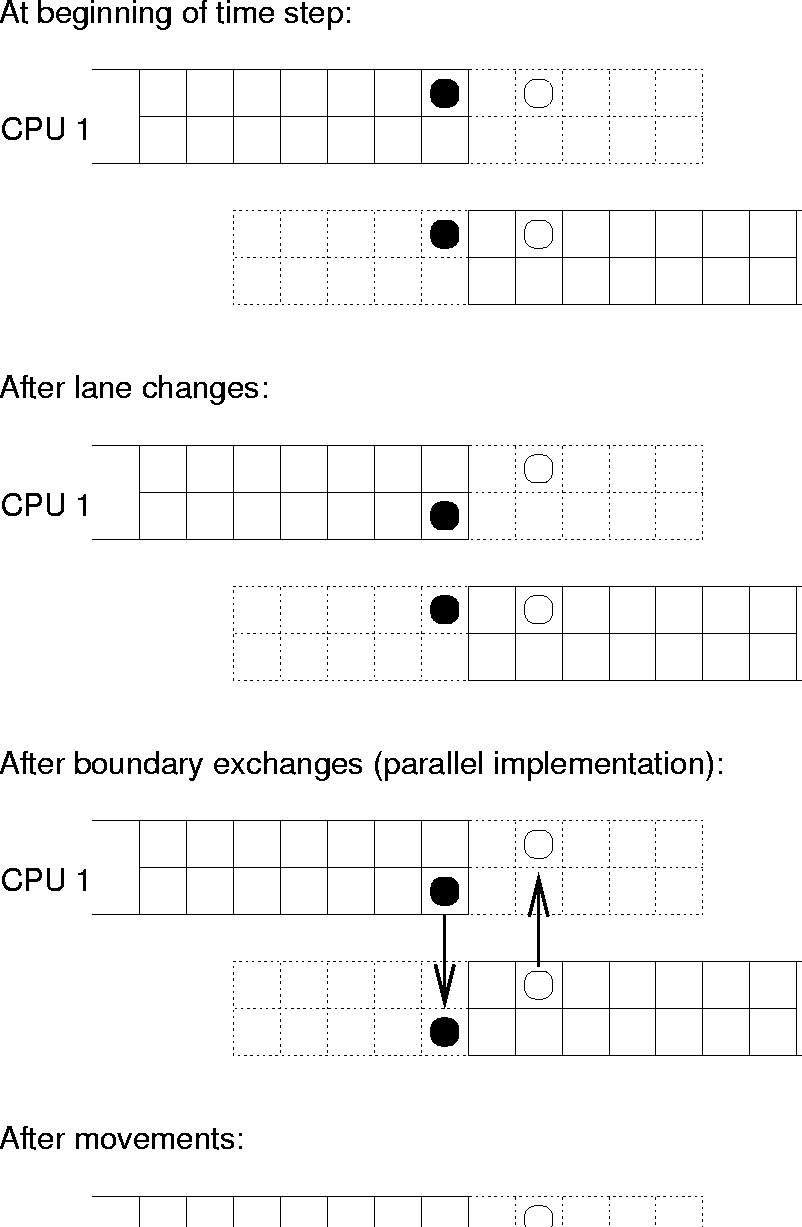
Figure 3: Example of parallel logic of a split link with two lanes.
The figure shows the general logic of one time step. Remember
that with a split link, one CPU is responsible for one
half and another CPU is responsible for the other half. These
two halves are shown separately but correctly lined up. The
dotted part is the ``boundary region'', which is where the link
stores information from the other CPU. The arrows denote when
information is transferred from one CPU to the other via
boundary exchange.