The problem with OD matrices is that they fix the travel demand once they have been derived. Thus, they fail to generate the effect of ``induced'' travel, which usually happens when one expands capacity. For example, a new freeway may induce people to make more trips, thus increasing overall travel. This means that one needs a demand generation method that is elastic with changing supply.
Activity-based methods attempt to achieve this by generating directly what people do during a day and where; transportation demand is thus derived by connecting activities at different locations (Fig. 21.1). There are at least two different methods to generate activities: econometric, and heuristic.
In principle, one can derive OD-matrices from activities, and many groups do this because it connects activity-based demand generation to existing models. This has, however, to be done with care since one loses important information. An important example of lost information are trip chains, where a person may go to work, may go shopping, and then home. If the person gets stuck on the way to shopping, the trip from shopping to home will take place later than anticipated; such effects do not get picked up in the OD matrix. Also, a universal reaction to changes in congestion seems to be to add or suppress intermediate stops at home, i.e. to replace home-work-home-shop-home by home-work-shop-home or vice versa. One would have to be careful to not suppress these possibilities when translating the trip chains into OD-matrices.
[[I have discrete choice theory now in ``background'']]
[[dennoch k"onnte man fast alles hier lassen]]
[[need to sort out the ![]() ]]
]]
Econometric methods (15,38) are based on
random utility theory, which will be explained in more detail in
Chap. 29. An often-used choice model is
the so-called logit model. If there are several options ![]() ,
then the logit model predicts that the probability to select option
,
then the logit model predicts that the probability to select option
![]() is
is

[[have used ![]() in dep time choice. should use same notation as
ben-akiva]]
in dep time choice. should use same notation as
ben-akiva]]
For demand generation, one needs to make ![]() dependent on the
attributes of the options, and on the properties of the individual
under consideration. A typical assumption is to make this dependence
linear:
dependent on the
attributes of the options, and on the properties of the individual
under consideration. A typical assumption is to make this dependence
linear:
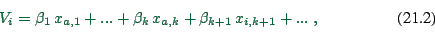
where the
![]() are person attributes, and the
are person attributes, and the
![]() are option attributes. For example, one could have
are option attributes. For example, one could have
[[find one with bus, car, income]]
Utility theory assumes that the utility a person ![]() sees in a certain action
sees in a certain action ![]() is composed of a measurable and a
non-measurable part:
is composed of a measurable and a
non-measurable part:
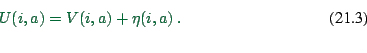
An often-used discrete choice model is the so-called logit model. Its main assumptions are:
![\begin{displaymath}
F(\eta) = \exp[ - e^{- \mu \, (\eta - \gamma) } ] \ ,
\end{displaymath}](img233.png)
![\begin{displaymath}
f(\eta) = \mu \, e^{- \mu \, (\eta - \gamma) } \,
\exp[ - e^{- \mu \, (\eta - \gamma)} ]
\end{displaymath}](img234.png)
The ![]() and
and ![]() are estimated from surveys, for example
via maximum likelihood methods. A sample of the population with
different car and bus travel times is asked about their choices, and
the
are estimated from surveys, for example
via maximum likelihood methods. A sample of the population with
different car and bus travel times is asked about their choices, and
the ![]() are determined such that the probability according to
Eq. 21.6 to re-generate the survey is maximized.
are determined such that the probability according to
Eq. 21.6 to re-generate the survey is maximized.
For applications inside a transportation simulation, this becomes a lot more complicated. An implementation for Portland/Oregon (17) determines activity patterns (for example home-work-home or home-work-shop-home), activity timing, activity locations, mode choice, etc. As long as one wants to treat all alternatives simultaneously, this has the problem that the number of coefficients grows exponentially. For example, if one has five activities patterns, and three modes of transportation, this means 15 different choices and thus 15 parameters. If however one does not treat the alternatives simultaneously, one can make mistakes: For example, a person could have a strong preference for a pattern home-work-home-shop-home when averaged over all possible circumstances, but may prefer home-work-shop-home when really good bus service is available. When choosing first the pattern and then the transportation mode, this information gets misrepresented.
Heuristic methods
The econometric method has a solid theoretical foundation, and it is currently the only method that is functional for transportation simulations. However, sometimes it seems like it does not really represent how people behave. The discrete choice method pretends that people calculate utilities for all possible alternatives and then choose the alternative with the highest utility. (Remember that the randomization just comes in because of ``unobserved attributes''.) However, people do not do this. For example, they may discard an activity pattern home-shop-work-home right away without calculating the utilities of all possible constellations.
Heuristic methods attempt to better represent such human planning processes. For example, research shows that humans make their planning decisions on many time scales simultaneously (37). The time for work is usually alloted way in advance, shopping may be planned a day in advance, and then the whole schedule may be changed short-term because the child gets sick. Prototypes for such models exist, but they seem currently far away from being operational in any meaningful way.
It should be noted that heuristic and econometric methods can be combined. For example, one could use a heuristic method to determine which decisions are made how far in advance, and use an econometric method to make the actual decision. Or the econometric method could calculate the probability for each activities pattern, the heuristic method could decide to retain the two most important patterns, the econometric method than could calculate the utilities for these two patterns for all mode and time combinations, etc.
Summary of activities-based methods
Activities-based demand generation models are a promising method for transportation simulation. Some implementations of these methods have reached the state where they can be used for actual applications (18). However, so far there are only very few results about coupling these methods together with transportation micro-simulations, as intended with the transportation planning simulation packages described in this article. The only functional system that we are aware of uses a very simple method of demand generation; it is described in the appendix. But we are optimistic that research in the next couple of years will expand the boundaries in these areas enormously.
![\begin{displaymath}
P(bus) = {\exp[ - \beta_b \, t_b ] \over
\exp[ - \beta_b \, t_b ] + \exp[ - \beta_c \, t_c ] } \ .
\end{displaymath}](img237.png)